ÇATALHÖYÜK 2005 ARCHIVE REPORT
| |
SUPPORT TEAMS
Database & IT Team
Team: Mia Ridge, Richard May, Dave Mackie.
Abstract
Our goals are to develop and improve applications that support the recording and analysis of the Çatalhöyük Projects archaeological research and data; and to improve access for the project team and the public to Çatalhöyük data.
The work of migrating stand-along Access databases to a central form, migrating non-Access interfaces to the project format, and application development and enhancement continued in 2005.
We expanded on the work on artefact-led recording we began last year. This began with work towards using shared lists of values for recording different types of artefacts of the same material in preparation for the centralisation of previously unlinked databases. In conjunction with the development of the core/extension model and the increasing use of views to create new insights from existing data, this lead to the re-thinking of the artefact recording model. This model has exciting implications for the project as a whole.
We work with a design philosophy that underlies all development and integration work for the Çatalhöyük project. The database is designed to be flexible, accessible and extensible.
Özet
Amacımız, Çatalhöyük’deki arkeolojik araştırma ve veri toplama bünyesindeki kayıt ve analiz çalışmalarını destekleyen uygulamaları geliştirmektir.
Access veri tabanı programını merkezi bir sisteme ve Access’in dışındaki alanları proje formatına bağlamayı amaçlayan çalışmalar 2005 sezonunda da devam etti.
Geçen sene başladığımız eser üzerinden yürütülen kayıt çalışmalarını genişletmeye devam ettik. Bu çalışma, önceden birbirine bağlı olmayan veri tabanlarının merkezileştirilmesi ve aynı materyalden olan farklı eserlerin kaydı için hazırlanan paylaşımlı değer listelerinin kullanılması ile başladı. Ayrıca, merkez bir model geliştirilmesi ve daha önceden varolan verilerin yeniden gözden geçirilmesiyle birlikte bir eser-kayıt modeli üzerinde tartışıldı. Bu model, Çatalhöyük projesi için önemli olacaktır.
Çatalhöyük projesiyle ilgili tüm geliştirme ve bütünleme çalışmalarının altında bir dizayn filozofisi yatmaktadır. Ulaşılabilir, değiştirilebilir ve geliştirilebilir bir veri tabanı oluşturmaya çalışmaktayız.
Background to MoLAS’ partiation
The Museum of London Archaeology Service (MoLAS) was invited to join the project because of our experience developing large archaeological database systems. The Çatalhöyük project had outgrown its existing IT infrastructure and needed a robust, stable and extensible database system.
Our goals are to develop and improve database applications for the recording and analysis of the Çatalhöyük Projects archaeological research and data, and to improve access for the project team and the public to Çatalhöyük data.
Mia Ridge is the Database Developer for the Museum of London Group, developing bespoke applications with Oracle forms and other technologies as appropriate. Rich May is the Network Manager for the Museum of London. Dave Mackie is a Senior Geomatics Officer at MoLAS. Tuna Kalaycı is a student who helped write and present training materials and helped with general support.
We are very grateful for the generous sponsorship from Lynn Meskell, Columbia University, towards employment of a dedicated assistant database developer for a 6-month period.
Initial investigation
The original database design and structure was well structured and much valuable work had been done on the database previously. Some problems had, however, arisen over the years as the database grew and different specialists brought their own systems based on a mixture of applications and platforms.
It was difficult for specialist databases to use live field or excavation data, as it was not available in a single central source. It had also become almost impossible to run queries across excavation seasons or areas, or produce multi-disciplinary analysis , as there were disparate unrelated databases for each area of study. Within many specialisms the data set has been broken up into many different files - for example, excavation was split into Bach, Team Poznan, Cambridge Teams etc - and some teams were creating separate files for different years.
In many cases, referential integrity was not properly enforced in the interface or database structure. While the original database structures included tables to supply lists of values to enable controlled vocabularies, the interfaces were using static rather than dynamic menus on data entry interfaces. Primary and/or foreign keys were not implemented in some databases, leading to the possibility of multiple entries, anomalous data or incorrect codes being recorded. There was little or no validation on data entry.
Infrastructure decisions
The existing infrastructure was Microsoft Access based, and after consideration for minimal interruption to existing interfaces, and for the cost to the project of completely redeveloping the forms on another platform, these applications were retained.
A decision was made, however, to centralise the back end serving of the full set of the databases. After investigation into the costs, available support and existing technical environment, Microsoft SQL Server was chosen.
Our first task was to implement an enterprise-strength database server, retaining the existing Access interfaces. We spent considerable time merging multiple disparate datasets and dealing with data integrity problems arising from un-validated data entry in order to produce a centralised dataset.
We also implemented (or re-implemented) relational integrity and worked on the import, validation, and integration of isolated data sets and forms. This work was largely completed in 2004.
After the 2004 season, we transferred the central database from the Çatalhöyük site server to the Cambridge server, and provided team members with versions of their familiar Access forms that connected directly to the Cambridge server. We provided online documentation for team members on setting up the connections necessary.
These forms were also used to access the central server over the on-site network in the 2004 and 2005 seasons. In accordance with our aim to provide multiple points of access to a single central data set, the database is accessible to a variety of applications over the internet. The central database server supports Open DataBase Connectivity (ODBC), a standard database access method so team members can also download raw or compiled data into any ODBC-compliant application, such as FileMakerPro, SPSS, Oracle, Access, Excel, Word, ArcView GIS, etc.
As a result:
-
The integrated Çatalhöyük dataset is accessible across years, teams, and areas of research
-
Live data is available over the internet for team members for download into any ODBC-compliant application
-
Cross-discipline analysis is possible.
Current database development
The work of migrating stand-along Access databases to a central form, migrating non-Access interfaces to the project format, and application development and enhancement continued in 2005.
In 2005, we expanded on the work on artefact-led recording we began last year. This began with work towards using shared lists of values and core data for recording different types of artefacts of the same material in preparation for the centralisation of previously unlinked databases. In conjunction with the development of the core/extension model discussed below and the increasing use of views to create new insights from existing data, this lead to the re-conception of the artefact recording model. This model has exciting implications for the project as a whole.
We work with a design philosophy that underlies all development and integration work for the Çatalhöyük project. The database is designed to be flexible, accessible and extensible.
This year, our focus has been:
-
Creating an extensible system architecture responsive to the Çatalhöyük methodology
-
Improving Access forms to help improve the quality of data entry by continuing to implement referential integrity and validation
-
Providing documentation and training to help team members use the database effectively
-
Meeting with specialists to develop new applications
-
Continuing the integration and centralisation of stand-alone data sources and applications
-
Integrating image and other media databases with forms and reports
In order to accomplish this, we have worked on related matters such as reliability, validation, and permissions.
Permissions
As the central database is used more intensively, the project requires a formal permissions model. In general, most team members will have read and write access for all tables related to their specialism and read-only access for all other tables. This will be largely transparent to the user, as the permissions model relates to specialist teams, and their Access interfaces which present relevant interfaces from the centralised database as specialist databases will not appear to change.
Validation
Validation at the point of data entry improves the quality and reliability of data. It enforces the use of agreed terms, such as area lists, or data formats, such as date and numerical formats. Validation means that data is more consistent and consequently complex analysis is both easier and more reliable.
The increasing use of ‘views’ or queries to create new databases from existing content also relies on validation. To ensure search terms such as materials or find types are reported reliably they must be entered with consistent spelling and case, ideally using a list of agreed terms.
‘Lists of values’ (LOVs) are drop-down menus that allow users to select one of a set of terms in a data entry field. LOVs can be static, where the values are hard-coded, or dynamic, where values are drawn from another table or query.
While validation on data entry is important, the nature of the Çatalhöyük project also requires that validation is flexible and non-dogmatic. The correct implementation of dynamic lists of values means that new or amended terms added to the underlying code tables are immediately available to all users.
Validation will be enforced at both the back- and front-end, with user-friendly error messages on the front-end.
Extensibility
During the 2005 season, we formalised a model of core and specialist data, in response to the challenges of making basic data accessible to all team members while incorporating different recording methods for particular specialisms over the life of the project.
Core data can be defined as un-interpreted inventory level, excavation and field data. It is intellectually accessible and comprehensible to non-specialists. Core data should ideally include basic information like measurements. Core values must always be complete for a particular record.
Specialist data incorporates interpreted data or specialist technical analysis. Specialist data must always link back to core tables. Extension tables in one database may appear as core tables in another, enabling increasing levels of specialisation.
Code tables providing agreed terms for dynamic lists of values can be linked to core or extension tables as appropriate.
The model of core and extension data solves several of the problems we first discovered when investigating the Çatalhöyük databases, including rescuing incompatible or incomplete data sets. These are the result of different recording techniques and methodologies between seasons, specialists and teams.
The model allows us to rescue core inventory data from otherwise undocumented specialist data sets. It also allows us to compare core data recorded by different specialists with different research interests, so that the recording they do at a basic level is available for re-use by other specialists and team members.
Applying a core data structure within every application means that basic, inventory level information is available consistently within any specialist database, over time, areas and teams.
Extension data structures on core data allows for the needs of future specialists and research by allowing people to build specialist data on existing data sets without interrupting existing data or interfaces.
It also allows new teams to start recording inventory-level data quickly while simultaneously developing their specialist recording structures and interfaces. In previous years, we realised it was difficult for specialists to provide a definitive statement of their recording and analysis needs while still completing an initial survey of their material.
The core/extension model has benefits for interface design. Core fields can be designed to make inventory level data entry as efficient as possible, while specialist interfaces can be designed to prompt for more discussion based on previously entered data.
The model also suits the separation of interfaces. For example, different specialists can record completely different data about the same artefact using interfaces tailored particularly to their research, without concern for other interfaces onto the same content.
In practice, specialist applications might involve multiple layers of core/extension tables as their recording model develops but the same philosophy of core and (increasingly) specialist data applies.
The existing faunal database is an excellent example of model of core data with specialist extensions. All faunal finds are recorded to a certain level of detail, and some artefacts are recorded in minute detail. This means that faunal specialists have a complete basic data set for some forms of analysis, but they do not need to record every artefact in that level of detail.
The archaeobotany database is another example of the core/extension model. Several teams have worked on archaeobotany data over the years, and each has used a different recording model. Working with the specialists, data from different years can be migrated into a structure that records baseline data based on the flotation logs, in core tables. Current specialist data can be recorded in tables that extend from this core data set. Storing sub-sets of specialist data recorded in different years in specialised extension tables allows this information to remain accessible without affecting the ‘completeness’ of the core data set.
Shared lists of values
Last year, as part of meetings with specialists about the normalisation and reconfiguration required before centralising their databases, it became apparent that certain core technical or material values were being recorded in several different specialist databases, often with overlap between the lists of values used to record those values. This meant that value lists, and potentially fields, could be shared between specialist databases when the databases were centralised.
For example, as we worked with clay artefact specialists last year, we realised that each specialist was recording similar technical data with similar value lists in their separate specialist databases, such as pottery, clay balls, stamp seals, and figurines.
Sharing agreed codes or lists of values between specialist databases enables a common language and creates the potential for more powerful cross-discipline analysis.
The implementation of shared lists of values as part of the recording of interpretative aspects of an artefact allows the direct comparison and analysis of artefacts of the same type and different materials. For example, the characteristics of stone, bone, shell, glass and clay beads could be analysed and compared, regardless of the material from which they were constructed.
The reverse is also true - it allows the direct comparison of artefacts of the same material without concern for different artefact types.
Shared lists of values becomes even more powerful when combined with views, allowing data to be re-contextualised and reconfigured regardless of the specialist database in which it was originally recorded.
Defragmenting artefact recording
This year we further developed our idea that artefacts can be recorded as core fields first, moving from technical or material recording to interpretative or specialist recording if and when it is supported by the characteristics of the artefact itself, rather than recording artefacts through the filter of specialist interpretation that look to fit it into a preconceived model.
Last season our decision to implement shared lists of values and discussion with specialists about the difficulties of recording indeterminate artefacts in databases designed for specialist recording lead to the development of a re-centralised model of artefact recording. As we work towards a completely centralised database, it will be possible to begin recording artefacts in core material and technical fields, moving onto specialist technical and interpretative recording if, and when, it is supported by the artefact itself.
Previously, artefacts were assigned to specialists and were subtly but implicitly labelled by the specialism and specialist application within which they were recorded. We discussed the difficulties of recording indeterminate artefacts in specialised databases with specialists during the 2004 season and discovered that beyond the data entry difficulties we were initially asked to investigate, the use of isolated specialist databases may bind the artefact to an implicit interpretation limited by the method or location used to record its materiality. Additionally, recording in individual isolated databases leads to a fragmented data set for the project as a whole.
Under the proposed model, artefact recording will begin with material-based recording. Core material tables record the existence of the artefact, link it to the finds and excavation databases, and record basic technical information about the artefact. Information about the condition and dimensions should also be recorded at this stage. Depending on the characteristics of the artefact, more detailed technical and material information can be recorded in related forms. The recording process moves on to more specialised recording and analysis when it is supported by the properties of that artefact.
Recording all artefacts in core tables enables incomplete, miscellaneous and indeterminate artefacts to be recorded without affecting the quality of the entire dataset, rather than requiring incomplete recording in specialist tables.
It avoids forcing an interpretation on an artefact at an early stage for convenience during data entry. The recording and analysis moves from the objective to the subjective, the general to specialist, from technical to interpretative data. For example, this model saves recording an indeterminate blob as a ‘figurine’ or ‘clay ball’ when it may not have enough surviving characteristics to determine it as either.
Implementation of the model should also allow the probability of interpretation to be recorded.
Further advantages are that the model also allows for the inventory level recording of artefacts that are not being studied by a specialist. Inappropriately specialist data is not recorded ‘just in case’. If a specialist comes to research on site, they will be able to make use of the inventory level data without throwing out specialist data that may not tie in with their particular research objectives. The core/extension model discussed earlier means they will be able to expand on the data recorded without affecting the overall data set.
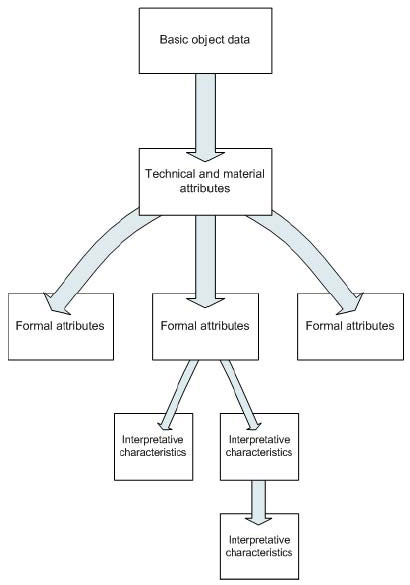
Figure 125. Diagram showing the defragmented recording model.
The clay/ceramics teams will be the first to implement this approach. We held a meeting on site, and as a result they will discuss between themselves which fields are core, which are intermediate, and which are entirely specialist and form-based. In the interim, they were to keep recording in their existing applications (usually FileMaker Pro).
This approach is exciting because it helps us alleviate the worst symptoms of working with computers and archaeological data. Computers deal with structured information, but recording analogue data in digital form can force artificial restrictions and the fragmentation of data. Well-structured data is important for analysis but information and context can be lost as data is broken into component parts.
One implication of this model is that the existing model of how artefacts are assigned to different specialists must be re-conceptualised. In theory, any specialist in a particular material could begin the initial recording of an artefact. Ideally, as the characteristics of the artefact are recorded, it would guide the user towards using particular data entry forms, which would prompt for more information based on what has already been entered. The point at which an artefact would be handed on for specialist interpretative recording would be determined on an application-by-application basis in consultation with specialists.
One advantage of this recording model is that specialists with more skills and experience in technical aspects could help specialists with fewer technical skills.
New insights from existing data
An exciting development this year was the team members’ use of views onto the central database to create new insights from existing data. While materiality may have been the primary basis for initial recording and analysis, views allow the grouping of materially unrelated artefacts by interpretative category, encouraging the reconstitution and re-contextualisation of artefacts.
While the technology behind views is of course not new, the ability to create views on the central database that span specialisms, teams and areas is a result of the previous centralisation work. It is closely related to our re-thinking of artefact recording in 2004.
Views (‘queries’ in Access terms) are like virtual windows that let users look at selected data from one or more tables. They allow users to create customised tables tailored to specialist requirements.
Queries can be saved within Access, and used as if they were traditional database tables. They allow users to build complex relationships and parameters into the design of a query, save it into their database, and view live data from the database each time they are run. New queries can be built on existing queries, allowing users to build complex queries without having to code complex SQL (Structured Query Language) statements. We created a new interface, the ‘AllTables’ database to help team members create effective queries.
Using views onto existing content, we can effectively create what appear to be new databases, which can be extended to allow the recording of specialist data, but does not require the re-entry of existing data from other databases. By putting existing data in a new context, fresh and innovative methods of analysis and engagement with the artefact are possible. Forms to record specialist data based on views can be added to new databases, encouraging further analysis.
For example, some team members began constructing databases based on views, such as an architectural analysis/building materials database based on queries for particular phrases in certain fields of the excavation database, with links to the diary and other databases. Team members were also looking at constructing a beads database, based on artefacts recorded in several different material-based applications. Views can also be used to reconstitute layers and contexts.
Views can become core tables and form the basis of new databases, linking to extension tables of specialist interpretation and discussion.
The use of views relies on reliable data – the consistent use of terms, correct spelling, etc, becomes even more important. We will work with team members to clean existing data sets and implement validation and guidance on data entry interfaces as required.
Accessibility
The work we carried out last year means that team members have direct access to the entire data set via the ‘back-end’ database. This year we have worked on making the process easier and more accessible by providing examples, training and documentation.
The figure below demonstrates the range of applications that can be used to interrogate the central database.
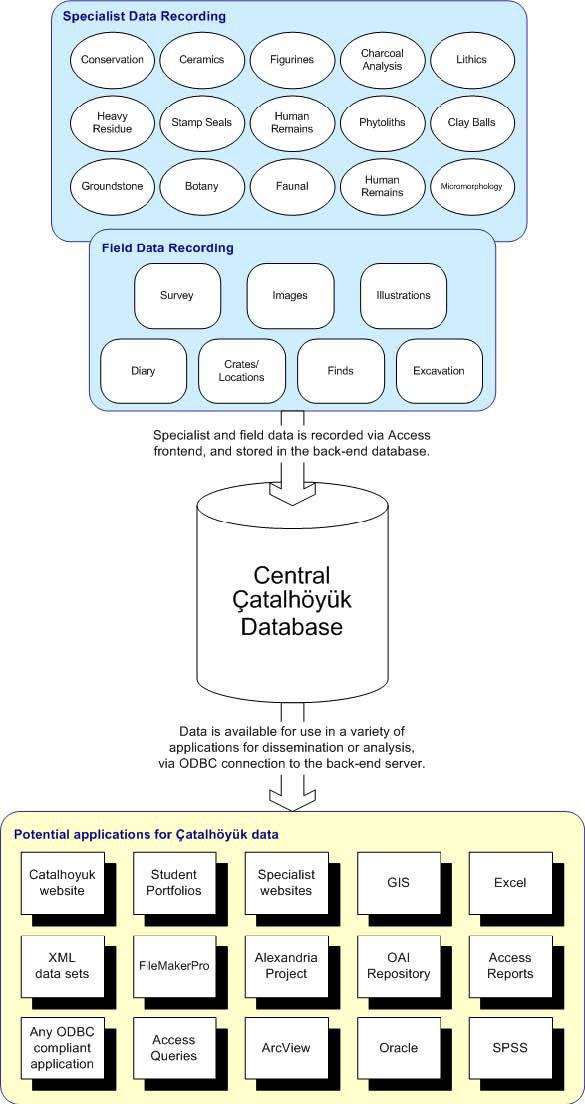
Figure 126. The central Çatalhöyük data is available online to a range of applications.
The core-specialist design paradigm is vital for maintaining accessibility. As new database applications are developed, the use of core tables provides access to basic data for all team members.
As the back-end is exposed to the user, consistent naming conventions naming for tables has a new importance. Once users understand the development model, they should be able to find or guess the names of the tables they need easily. To support this, table names should be clear, self-explanatory and consistent. Currently, table names are generally in the form of [Databasename: Basic: xxx], [Databasename: Data Type] and [Databasename: Code: xxx], where Databasename stands for the general title for the discipline and their associated database.
The existing naming convention allows spaces in table names and is therefore not ideal. However, at this stage the tables should not be renamed as they are used in existing queries and forms. The use of aliases is a possible future solution to allow phased re-naming should it be required.
Team members can download entire datasets or run queries to selectively return data. The user can tailor queries to meet their exact requirements. This back-end access means that users must have access to documentation so they can determine which tables contain the information they need, and which tables are required to link and create the relationships between those tables.
When using specialist data, team members may need to contact the appropriate specialist to discuss their recording methods in order to interpret their data correctly.
Training and documentation
While on site we, with Tuna Kalaycı, prepared and presented a training session for all database users on designing, creating and using Access queries. Training and documentation are crucial for making data accessible and usable.
We also prepared a training document that included the material covered in the training session and provided more detailed and more advanced information on using the Çatalhöyük database applications for query and analysis.
The ‘All Tables and Queries’ was built on-site in response to discussions with a range of team members. It allows project members to create cross-disciplinary queries and reports with user-friendly tools.
Overall, the aim is to produce a library of Çatalhöyük-specific training documents.
Having provided the infrastructure to enable team members to create, save and share queries, we hope they will continue to build a shared library of reports and queries.
We will also work with users to convert commonly used queries into views on the back-end server for better accessibility to all ODBC-compliant applications.
Public presentation of data
Website
A meeting was held with Ian, Shahina and team leaders to discuss the options for publishing site data online.
It was agreed that core data - defined as ‘un-interpreted, inventory level, excavation and field data’ up to the present date would be published online.
Some specialist and unpublished data will not be available on the website until it has been published elsewhere. Each team leader will be able to state the extent to which their data can be published, listing any restrictions by content area (table and field) and by date.
Possible website functionality including the ability for members of the public to comment on site data were also discussed.
There will effectively be two websites - the public website, and a team website, with different levels of access, and different content. The team website will be password-protected.
The publication of partial data sets will require a careful explanation to the public of the coverage of data published online, e.g. year, fields, extent of data, info on context, e.g. excavation data is initial impression only.
The password-protected team website will contain instructions on using the database forms over the internet, and downloadable versions of the Access forms.
Other formats
As the database are centralised, it becomes possible to publish data in a variety of ways. These methods include Geographic Information Systems (GIS), and presentational database applications such as ArchaeoML.
Selected summaries of database work on site
We had many meetings with specialists to determine their requirements for recording and analysis.
As discussed above, we worked on the overall application architecture in response to these meetings and to the project requirements generally. Development of specific specialist databases continued off-site and will continue throughout the year.
The following is a summary of some of the meetings held on site.
These notes are intended to provide an insight into the processes of database development and as such, any requirements, analysis or solutions discussed should be regarded as a work in progress.
Architectural Analysis/ Building Materials: this application will be a view onto existing data, possibly with new tables and forms to record specialist interpretative information and discussion.
All Tables and Queries database: this was built on-site in response to discussions with a range of team members. It allows project members to create cross-disciplinary queries and reports with user-friendly tools.
For example, team members interested in Building Materials can link from a feature to related units, find the heavy residue data for those units, and tie it together with the relevant diary entries
The training session on-site presented this database to team members, and provided information and examples of query construction. The implementation enables queries to be shared between users and we hope users will build a library of queries.
The database documents all tables in the database. It requires that new tables be added (as ‘linked tables’) as they are added to the back-end database, either as parts of new applications or newly integrated data sets.
Beads: initial discussions suggest this will be a view onto existing data, re-contextualising content from several different materials-based databases. It may require documentation for excavators filling out finds sheets to ensure consistency in terms used.
Archaeobotany: after discussions with specialists, it was agreed that a core table based on the flotation log containing with all samples, and extension tables for current and previous specialist data should meet their requirements and provide a core inventory. The specialists did excellent work to match structures and data across years and specialists.
Clay objects, including stamp seals, figurines, pottery, clay balls and geometric shapes: met with building material, figurines and pottery specialists to discuss progressing the work begun on core fields and shared codes in 2004. This work will continue off-site in 2005/2006.
Excavation: on-going changes include intensive work on implementing lists of values as source for validation on data entry, to ensure current values are always available to users and on implementing a flexible permissions model. We also added the fields Fast Track, Not Excavated, Total Deposit Volume, and Dry Sieve Volume.
Faunal: an initial meeting was held with specialists about fixes, centralising, importing data and further functionality requests. Worked closely with the faunal team to implement fixes on codebook, relationships, the interaction between forms, defaults, and 0 vs. NULL issues. Also implemented help tips and buttons. Worked closely with a faunal team member who picked it up very quickly and was soon using the Access design view to implement value lists and input validation. We did some work in the VBA editor for more technical issues like carrying data between forms, button interactions and triggering saving when form loses focus. As most faunal team members used the updated version of the faunal database during the rest of the season, they had the benefits of improved layouts, updated codes, help screens, tighter validation and better workflow through the application.
Figurines: most of the requirements analysis and conceptual work was carried out last year. The initial goal was to redesign the existing data structures and interfaces for most efficient data entry, storage and analysis.
This entailed several meetings with the specialist to refine the data structures and to test and modify the application.
The specialist’s original structure was reasonably good but required a lot of normalisation, as originally there was one single table with 83 fields.
The original database seemed to be recording at least two types of information - material and representational - about two types of objects - figurines and somewhat undefined ‘blobs’. Rather than a simple conversion from FileMaker Pro, it was apparent that it was necessary to split the data structures and interfaces. This makes data entry simpler, reduces the chances of incorrect data entry, reduces the overall size of the database and makes searching more efficient. For example, tables recording data about clay and form representations should be split so that the user only records data for a form if it is a possible characteristic for that form.
After the initial meeting, a copy of the database was taken and the initial data set imported. A design showing proposed data tables and relationships was presented to the specialist to check assumptions about different relationships and types of information against her knowledge of the material. Once an initial design was agreed, interface design and application development began.
The interface and database designs went through an intense development period on site, with 12 iterations over 4 days. One of the reasons the design went through so many iterations was that the specialist was still conducting an initial survey of the material, and some initial assumptions about the information to be recorded changed as she got a clearer view of the collection. This affected her understanding of the recording requirements for the data structures, relationships and the forms interfaces.
Working under intense conditions had some interesting side effects. It became clear that specialists need time to consider and understand their requirements, especially when faced with a collection of objects for the first time.
At the end of the on site development work, the database was reasonably complex, and still requires further normalisation - the main table has nearly 40 columns, and there are nearly seventy tables in a three-tier relational structure, with one main form and several sub-forms ranging from core to specialist data, and displays from related central tables (such as unit sheets). This further normalisation will be carried out as of the overall design process for a centralised clay objects recording model.
The process of conducting requirements analysis for centralising all clay objects databases with a range of clay objects specialists gave a useful overview as to the shared recording requirements of clay specialists, which enabled the development of a new data model, as discussed above.
Finds, Crates and Locations, Finds Log: The system must have core tables to record the location of everything, but specialists can create their own tables to store specific information.
The Crates update has two parts - modifying it to allow non-crate locations such as museums, and adding extra fields for various specialists to record extra information and for museum accession numbers. Some work might also be necessary on the Finds Log database.
Post-season work includes combining the Finds, Crates and Locations, Finds Log databases into a single interface, called the Finds Register. It will include relevant forms from all previous databases. Extensive data cleaning will also be undertaken post-seasons.
Ground Stone: after discussion of the existing data sets, analysis and recording requirements, the specialist worked on matching existing data structures to her requirements. She produced a good structure for her data, which was normalised to resolve data integrity issues and achieve integration with the central database. Data sets with be integrated and this structure implemented before the 2006 season.
Human Remains: discussion about the recording and analysis requirements of this database began during the 2004 season and continued in 2005. The database must serve many different users - including excavators, archaeologists, specialists, and researchers - with potentially conflicting requirements.
This potential problem became an advantage, as these requirements lead to refinement of the core/extension model of data structures and recording for Çatalhöyük databases.
In summary, the core structure must be as simple and as closely related to the user’s view of the data being recorded as possible. The basic data needs to be available for use by any specialist, without training in the intricacies of a more elegant but more abstract system. The human remains team have specific recording requirements, which necessitate specialised data structures. They also have limited time for recording each skeleton and wish to limit the number of times each skeleton is handled so the application must support efficient data entry, including simple effective ways to indicate the presence or absence of bones as well as field conservation, condition and metric information for bones that are present. The application must also allow researchers to record further specialist data in detail without affecting the overall efficiency of the application.
The application will be designed so that future research and analysis requirements can be supported by data structures that ‘plug in’ to the main application structures.
The data structures must also solve the problem of recording the remains present uniquely, whether single, multiple, co-mingled, articulated or disarticulated, while linking back to assemblage or burial records where appropriate, and to the archaeological context of the find.
The team would like a visual mark-up system and the ability to print reports that can be used to check over remains.
Lithics: a meeting was held with the specialist to discuss existing data sets and future recording and analysis requirements. Existing Excel data sets will need normalisation and core/extension structures determined, in work to continue off-site with all relevant specialists.
| |
© Çatalhöyük Research Project and individual authors, 2005